Token Metadata API
A microservice that indexes metadata for all Fungible, Non-Fungible, and Semi-Fungible Tokens in the Stacks blockchain and exposes it via JSON REST API endpoints.
Service architecture
This section gives you an overview of external and internal architectural diagrams.
External architecture
The external architectural diagram shows how the Token metadata API is connected to three different systems, Stacks node, Stacks blockchain API database, and Postgres database.
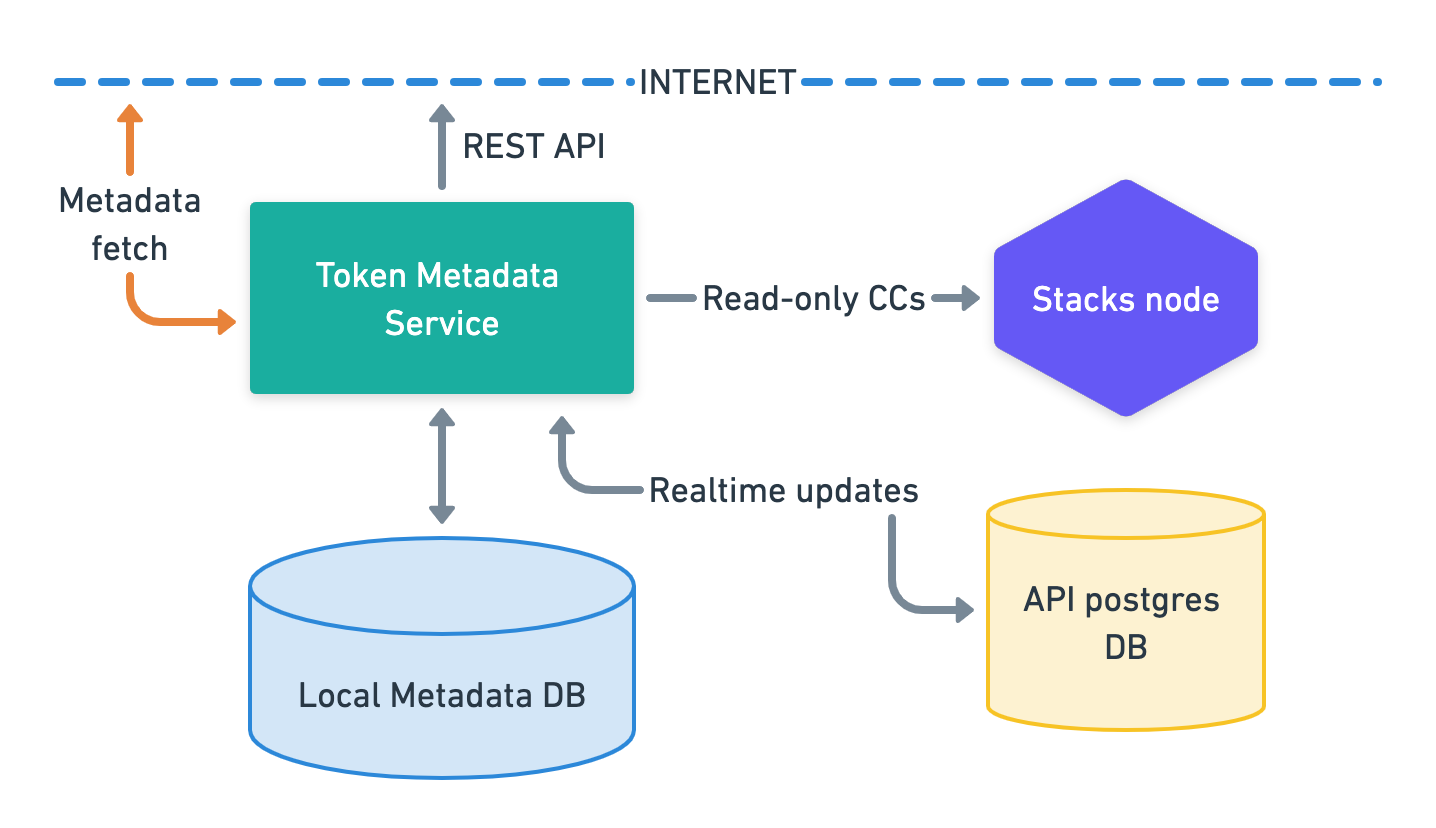
- Token metadata API interacts with Stacks Blockchain API database( referred to as Local Metadata DB in the diagram) to import all historical smart contracts when booting up and to listen for new contracts that may be deployed. Read-only access is recommended as this service will never need to write anything to this database(DB).
- A Stacks node to respond to all read-only contract calls required when fetching token metadata (calls to get token count, token metadata URIs, etc.).
- A local Postgres DB to store all processed metadata info.
The service needs to fetch external metadata files (JSONs, images) from the internet, so it must have access to external networks.
Internal architecture
The following is the internal architectural diagram of the Token metadata API.
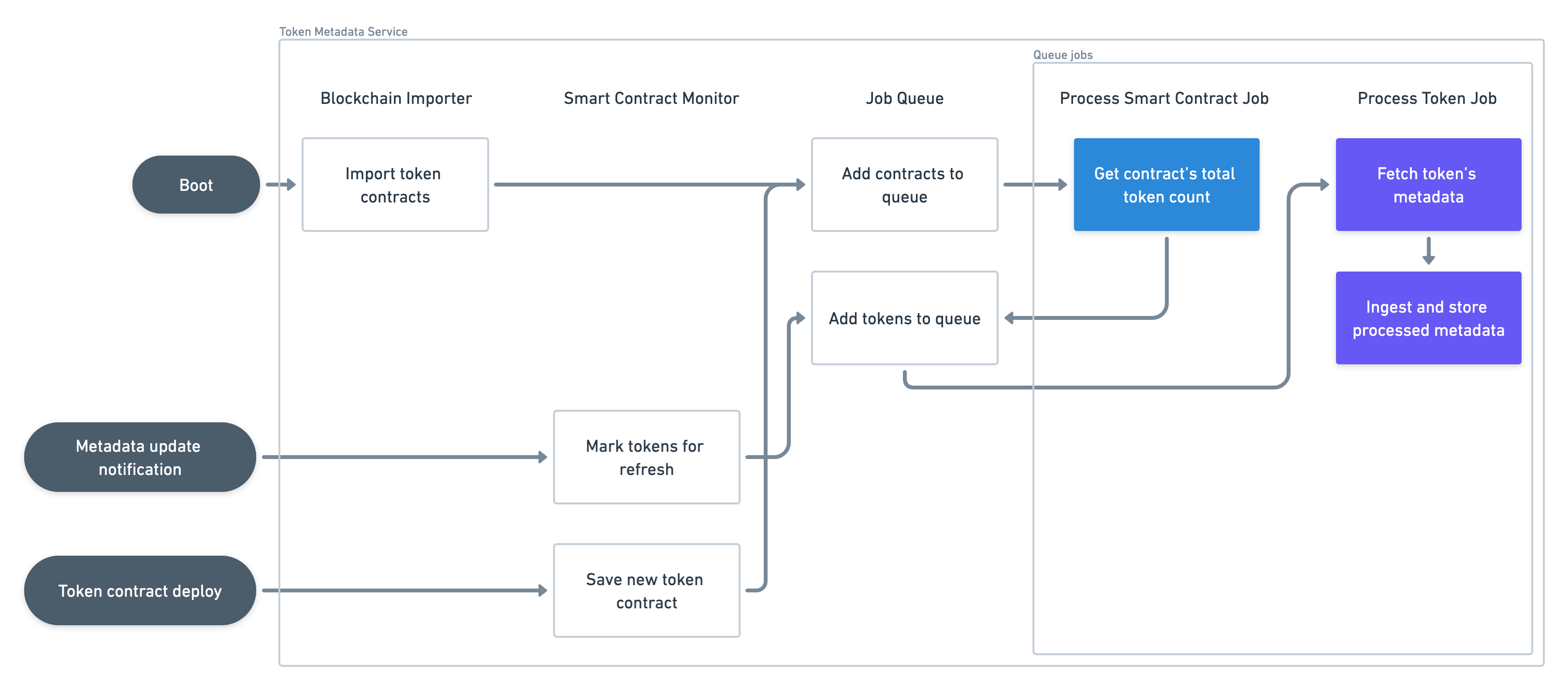
Blockchain importer
The BlockchainImporter is a component in the Token metadata API that takes token contracts from the API database. This component is only used on service boot.
It connects to the Stacks Blockchain API database and scans the entire smart_contracts table looking for any contract that conforms to SIP-009, SIP-010 or SIP-013. When it finds a token contract, it creates a ProcessSmartContractJob and adds it to the Job queue, ßso its tokens can be read and processed thereafter.
This process runs only once. If the Token metadata API is ever restarted, though, this component re-scans the API smart_contracts table from the last processed block height. So, it can pick up any newer contracts it might have missed while the service was unavailable.
Smart contract monitor
The BlockchainSmartContractMonitor component constantly listens to the following Stacks Blockchain API events:
-
Smart contract log events
If a contract
printevent conforms to SIP-019, it finds the affected tokens and marks them for metadata refresh. -
Smart contract deployments
If the new contract is a token contract, it saves the new token contract and adds the contract to the job queue for token processing.
This process is kept alive throughout the entire service lifetime.
Job queue
The role of the JobQueue is to perform all the smart contract and token processing in the service.
It is a priority queue that organizes all necessary work for contract ingestion and token metadata processing. Every job this queue processes corresponds to one row in the jobs DB table, which marks its processing status and related objects to be worked on (smart contract or token).
This object essentially runs an infinite loop that follows these steps:
- Upon
start(), it fetches a set number of job rows that are'pending'and loads their correspondingJobobjects into memory for processing, marking those rows now as'queued'. - It executes each loaded job to completion concurrently. Depending on success or failure, the job row is marked as either
'done'or'failed'. - Once all loaded jobs are done (and the queue is now empty), it goes back to step 1.
There are two environment variables that can help you tune how the queue performs:
ENV.JOB_QUEUE_SIZE_LIMIT: The in-memory size of the queue, i.e., the number of pending jobs that are loaded from the database while they wait for execution (see step 1 above).ENV.JOB_QUEUE_CONCURRENCY_LIMIT: The number of jobs that will be run simultaneously.
This queue runs continuously and can handle an unlimited number of jobs.
Process smart contract job
This job makes a contract call to the Stacks node to determine the total number of tokens declared by the given contract. Once determined, it creates and enqueues all of these tokens for metadata ingestion.
Process token job
This job fetches the metadata JSON object for a single token and other relevant properties depending on the token type (symbol, decimals, etc.). Once fetched, it parses and ingests this data to save it into the local database for API endpoints to return.
Features
- Complete SIP-016 metadata ingestion for
- Automatic metadata refreshes via SIP-019 notifications.
- Metadata localization support.
- Metadata fetching via
http:,https:,data:URIs. Also supported via customizable gateways:- IPFS
- Arweave
- Easy to use REST JSON endpoints with ETag caching.
- Prometheus metrics for job queue status, contract and token counts, API performance, etc.
- Image cache/CDN support.
API reference
See the Token metadata API Reference for more information.
Quick start
System requirements
The Token metadata API is a microservice with hard dependencies on other Stacks blockchain components. Before you start, you'll need to have access to the following:
- A fully synchronized Stacks node
- A fully synchronized instance of the Stacks Blockchain API running in
defaultorwrite-onlymode, with its Postgres database exposed for new connections. A read-only DB replica is also acceptable. - A local writeable Postgres database for token metadata storage
Run service
This section helps you to initiate the service by following the steps below.
- Clone the repository by using the following command:
git clone https://github.com/hirosystems/token-metadata-api.git
-
Create a
.envfile and specify the appropriate values to configure access to the Stacks API database, the Token metadata API local database, and the Stacks node RPC interface. Seeenv.tsfor all available configuration options. -
Build the app (NodeJS v18+ is required)
npm install
npm run build
- Start the service
npm run start
Stop service
When shutting down, you should always prefer to send the SIGINT signal instead of SIGKILL so the service has time to finish any pending background work and all dependencies are gracefully disconnected.
Using image cache service
The Token metadata API allows you to specify the path to a custom script that can pre-process every image URL detected by the service before it's inserted into the DB. This will enable you to serve CDN image URLs in your metadata responses instead of raw URLs, providing key advantages such as:
- Improves image load speed
- Increases reliability in case the original image becomes unavailable
- Protects original image hosts from DDoS attacks
- Increases user privacy
An example IMGIX processor script is included in config/image-cache.js.
You can customize the script path by altering the METADATA_IMAGE_CACHE_PROCESSOR environment variable.